





















.svg)












.svg)















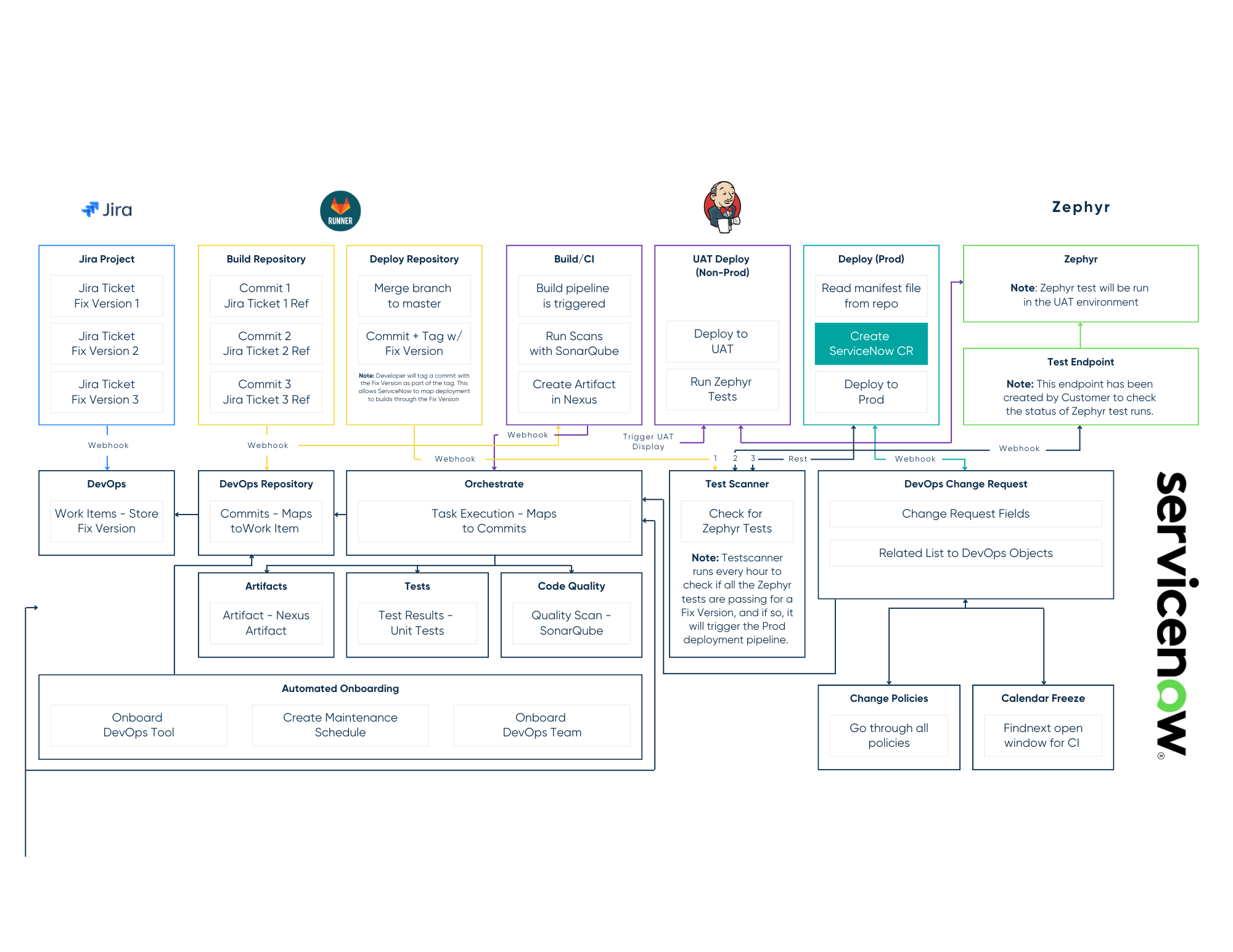
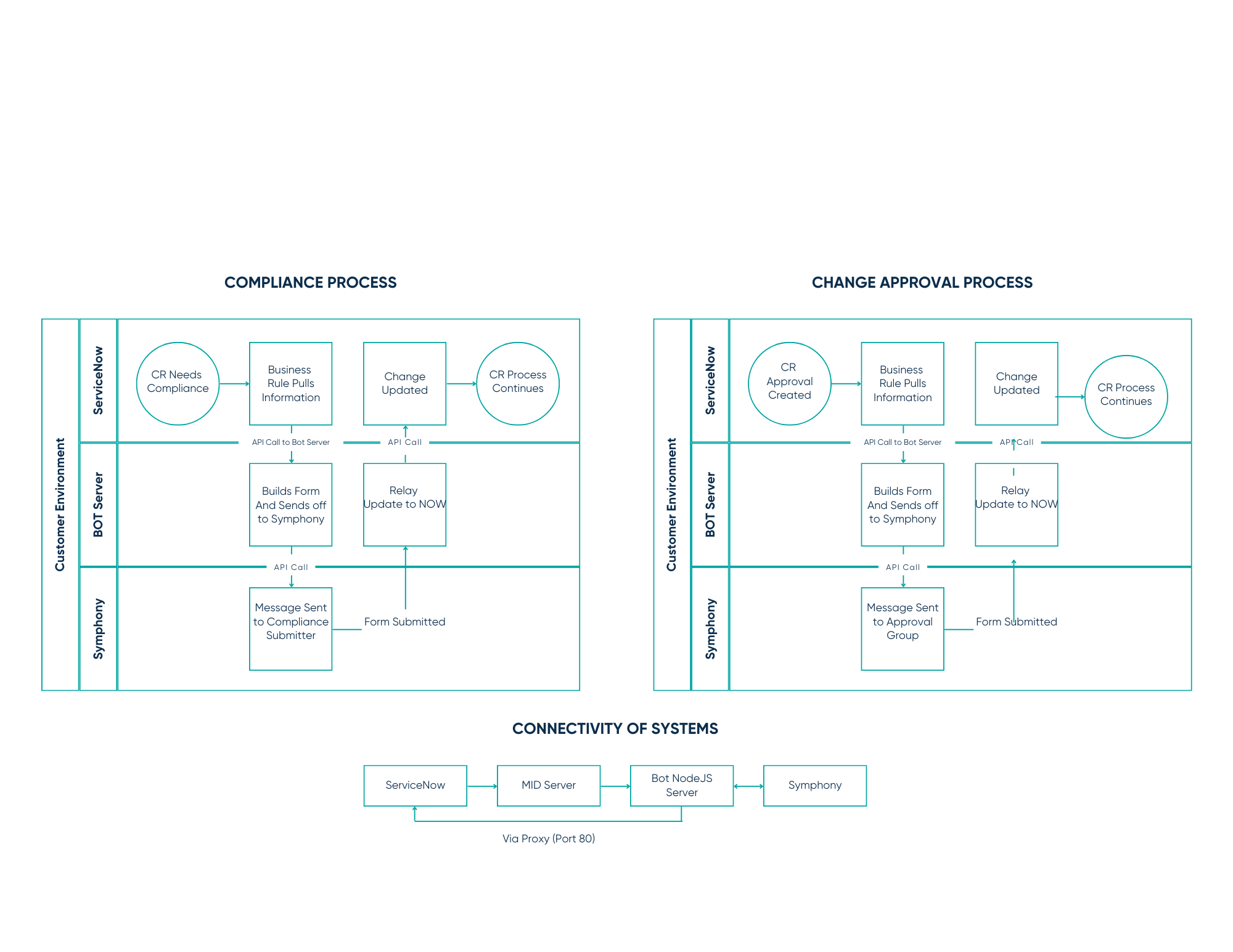




.png)


I've never written a Blog post before but I figured, why not now? A lot of what I've learned in my career so far has revolved around building the infrastructure and processes to accelerate the engineering teams ability to deploy code to production.
I'm personally not a developer and never have been. I studied Computer Engineering and focused mainly on circuit design, and then went on to a network-engineering role at my first job. Following my career in networking, I landed in operations and that's where I started learning more about the world of telemetry, logging, and making better systems that work more effectively together.
I'm hoping to use this blog to write about the different concepts I’ve learned from the great engineers and leaders I've had the opportunity to work with. The most important thing I’ve come to learn is that you need a good balance of engineering and culture. A good culture alone will not make up for legacy engineering skill sets, and great engineers will need a healthy culture to work in. I'm hoping to cover a range of things I've learned about engineering concepts and implementations we've done, using different tools, technologies, and methods, all of which have helped us get to the velocity we've looked to achieve. Ultimately, velocity is what unlocked the ability for innovation and tight feedback loops, and has been the guiding force for every organization I’ve been involved with.
A common phrase that you've likely heard before, and will likely hear again, is “fuck it ship it”. I've been hesitant to name the blog that, because of the potential controversy of using that word in a professional environment - but I suppose blogs aren't meant to be stuffy and professional? The reason I'm mentioning it in my first post, is because it's been important to me at all my jobs, and now the startup I'm part of. It comes from a place of comfort and confidence that the technology you have built, and the resiliency you have implemented in your stack, has really allowed you to deploy to production without any concern of outages or downtime. The first time I heard this term was from the manager that hired me at Wayfair. He actually had the phrase printed and hung up on a wall. His role at the time, which eventually became my job, was to ensure the stability of our e-commerce platform that saw over 20 million users a week and growing. Robert Clein was one of the most influential engineering leaders I've had the chance to work with, primarily for the culture he was able to build within the organization. The environment that Wayfair had built over time, and was inspired by everyone from its co-founders down to its interns, was one that enabled risk-taking, promoted trial and error, and assured everyone that mistakes were never frowned upon or blamed for.
This was the polar opposite from the company I had initially started my career at, where making major mistakes was almost a career-limiting move. We're all familiar with the environments that penalize engineers for making those mistakes. We've all worked in environments where we've had to sit through long-winded post-mortems, where we’ve had to get approval for any changes we want to make, and hold our breath anytime we touch a production system, to make sure we don't get scrutinized for taking something down. After having worked in the operations and production support space for over 15 years, I've come to realize that those environments have not been the most incentivizing, nor the most innovative and fast-paced.
Watching this perception shift over the past 6 to 7 years has been very impressive, especially with companies that were “born-in-cloud” over the last 10 to 15 years. A lot of those companies are SAAS based technology unicorns that tend to be built around new methods that were developed during the growth of those companies. A lot of those methods and concepts started with companies like Google, Facebook, and LinkedIn, and have now become the industry standard for organizations globally.
Nobody wakes up one morning thinking, "Today is a great day to take down our production application". Mistakes happen, and engineers will always have an element of human error. One of the most important things I've learned is that mistakes made by engineers are not a result of bad engineering, rather the result of a system that is not resilient enough. Any downtime that may happen in an environment usually happened because the system was not designed to protect itself well enough. That concept has been extremely important in exposing any opportunities to improve a system, and it’s ability to lose components without affecting the usability of the platform. Firing engineers for mistakes they make is a terrible way to build a culture of trial and error and innovation, which are two vital components in moving fast, building velocity, and ultimately getting code out faster.
I've been fortunate enough over the past three years to partake in a lot of different online webinars and blogs, which talk about these topics and let me share my experiences, and I’m hopeful that this blog post is interesting enough for you to want to read my future posts. If you have any questions about anything I ever write, please feel free to reach out to me directly at my email, or drop me a note on LinkedIn!


